
The Runaway AI Train
AI systems are increasingly contributing to their own development, potentially creating a runaway feedback loop once they match human AI researchers

AI systems are increasingly contributing to their own development.
Once they become as competent as human AI researchers, they will likely start self-improving at a runaway rate, creating the mother-of-all feedback cycles.
Take a moment to truly grasp what this means: AI could potentially enhance itself in a matter of days, weeks, or even faster in the near future. Remember this when someone confidently claims that certain AI capabilities are still far on the horizon.
Here’s what it may look like:
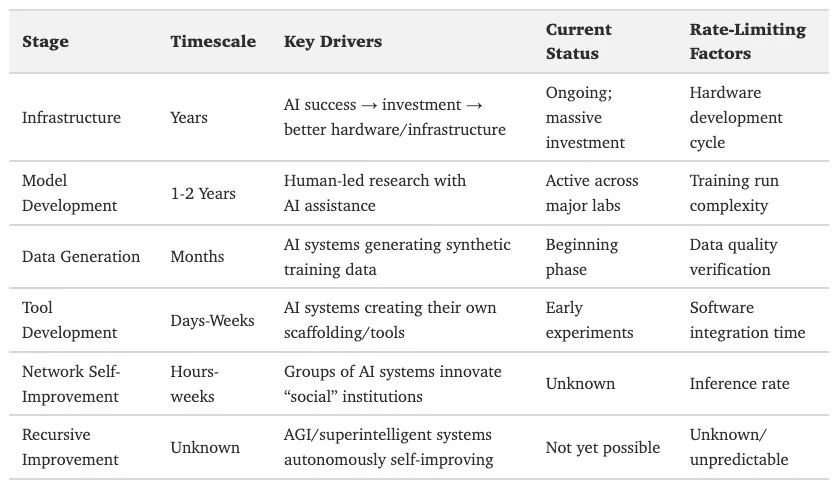
Leopold Aschenbrenner described this situation in his essay, Situational Awareness:
“We don’t need to automate everything—just AI research. A common objection to transformative impacts of AGI is that it will be hard for AI to do everything. Look at robotics, for instance, doubters say; that will be a gnarly problem, even if AI is cognitively at the levels of PhDs. Or take automating biology R&D, which might require lots of physical lab-work and human experiments.
But we don’t need robotics—we don’t need many things—for AI to automate AI research. The jobs of AI researchers and engineers at leading labs can be done fully virtually and don’t run into real-world bottlenecks in the same way. And the job of an AI researcher is fairly straightforward, in the grand scheme of things: read ML literature and come up with new questions or ideas, implement experiments to test those ideas, interpret the results, and repeat. This all seems squarely in the domain where simple extrapolations of current AI capabilities could easily take us to or beyond the levels of the best humans by the end of 2027.
The job of an AI researcher is also a job that AI researchers at AI labs just, well, know really well—so it’ll be particularly intuitive to them to optimize models to be good at that job. And there will be huge incentives to do so to help them accelerate their research and their labs’ competitive edge.”
The ‘RE-Bench’ benchmark was recently created to measure the ability of AIs to do AI research and development. It found that some of today’s AI models already beat human experts at large, open-ended tasks related to AI engineering. They were also often faster and less costly.
“We compare humans to several public frontier models through best-of-k with varying time budgets and agent designs, and find that the best AI agents achieve a score 4x higher than human experts when both are given a total time budget of 2 hours per environment. However, humans currently display better returns to increasing time budgets, narrowly exceeding the top AI agent scores given an 8-hour budget, and achieving 2x the score of the top AI agent when both are given 32 total hours (across different attempts).
Qualitatively, we find that modern AI agents possess significant expertise in many ML topics -- e.g. an agent wrote a faster custom Triton kernel than any of our human experts' -- and can generate and test solutions over ten times faster than humans, at much lower cost. We open-source the evaluation environments, human expert data, analysis code and agent trajectories to facilitate future research.”
Jim Fan, Senior Research Scientist at NVIDIA and Lead of AI Agents Initiative, writes:
”Operational definition of singularity: we are not truly done until transformers start to research the next transformer. A less fancy term is AutoML, a decades-old CS topic. Singularity is AutoML at the extreme. AutoML is trading capital for higher intelligence without human babysitting.
Concretely, the model needs to read research papers, collect and curate data, manage a GPU cluster, monitor the training jobs, and select its own offsprings from silicon. Perhaps they can even peer review each other in an AI-led virtual conference. Basically long-context reasoning + multi-agent RL + evolutionary algorithm.
I don’t think we are very far away from this.”
We’re not there yet. But the incentive to automate AI R&D research has never been greater, and it’s increasingly a focus for frontier labs.
Summary
AI systems are increasingly contributing to their own development, potentially creating a runaway feedback loop once they match human AI researchers
The job of AI research is particularly amenable to automation as it's done virtually without physical bottlenecks and AI labs have strong incentives to optimize for this capability
Recent benchmarks show some frontier models already outperform human experts on AI R&D tasks by 4x when given a 2-hour time budget, and can generate solutions 10x faster at lower cost
Complete automation of the AI development cycle (reading papers, curating data, managing compute, monitoring training, selection) may be achievable in the near future